Next.js 1차 프로젝트 회고
1차 프로젝트가 끝난 후 연휴를 보냈더니 일주일이 훌쩍 지나갔다..🫠 더 늦기전에 언능 회고를 작성해보자
🎯 프로젝트 개요
요번 프로젝트는 수업 과정에서 배운 기업형 구조에 맞춘 설계 방식을 적용해 보는 것 + 데이터베이스 모델링 설계와 Next.js를 활용한 백엔드 구현을 함께 진행하며 전체적인 시스템 구조에 대한 이해와 시야를 넓히는 것이 핵심 목적이었다. 익숙하지 않은 방법이지만 실제 기업에서는 유지보수성, 확장성, 협업 효율성을 고려해 보통 아래와 같은 설계 원칙을 고려한다고 한다.
- 도메인 중심 설계(기능 중심❌ 실제 비즈니스 영역(업무 단위) 기준으로 구조화)
- 클린 아키텍처 적용을 통해 각 계층의 책임과 역할을 분리
짧은 기간 동안 진행된 프로젝트였지만, 직접 백엔드 구현을 경험하며 그동안 느꼈던 막연한 두려움과 부담을 해소할 수 있었던 의미 있는 시간이었다.
+) 프로젝트 마무리 멘토링에서 프론트엔드에서도 클린 아키텍처 구조를 사용하는지에 대해 여쭤봤는데, 멘토 분의 설명에 따르면 프론트엔드는 클린 아키텍처처럼 엄격하게 나누기보다는, 비즈니스 로직의 변화(기능 요구사항이 변하거나 추가되는 상황)에 따라 구조를 빠르게 바꾸기 쉽도록 설계하는 게 일반적이라고 한다.
1. 프로젝트 소개
프론트엔드 개발자들과 기술 면접 질문과 답변을 공유하기 위한 기술 면접 준비 플랫폼
2. 프로젝트 팀 구성
3인
3. 프로젝트 기간
2025.04.07~2025.04.28
4. 사용한 기술 스택
- 프레임워크: Next.js, TypeScript
- 데이터베이스: Supabase
- 스타일링: Tailwind CSS, Shadcn/UI
- 전역 상태 관리: Zustand
- CI/CD: Github Actions
- 배포/호스팅: Vercel
- 코드 품질 도구: ESLint, Prettier
- 기타: Notion, Figma, Discord
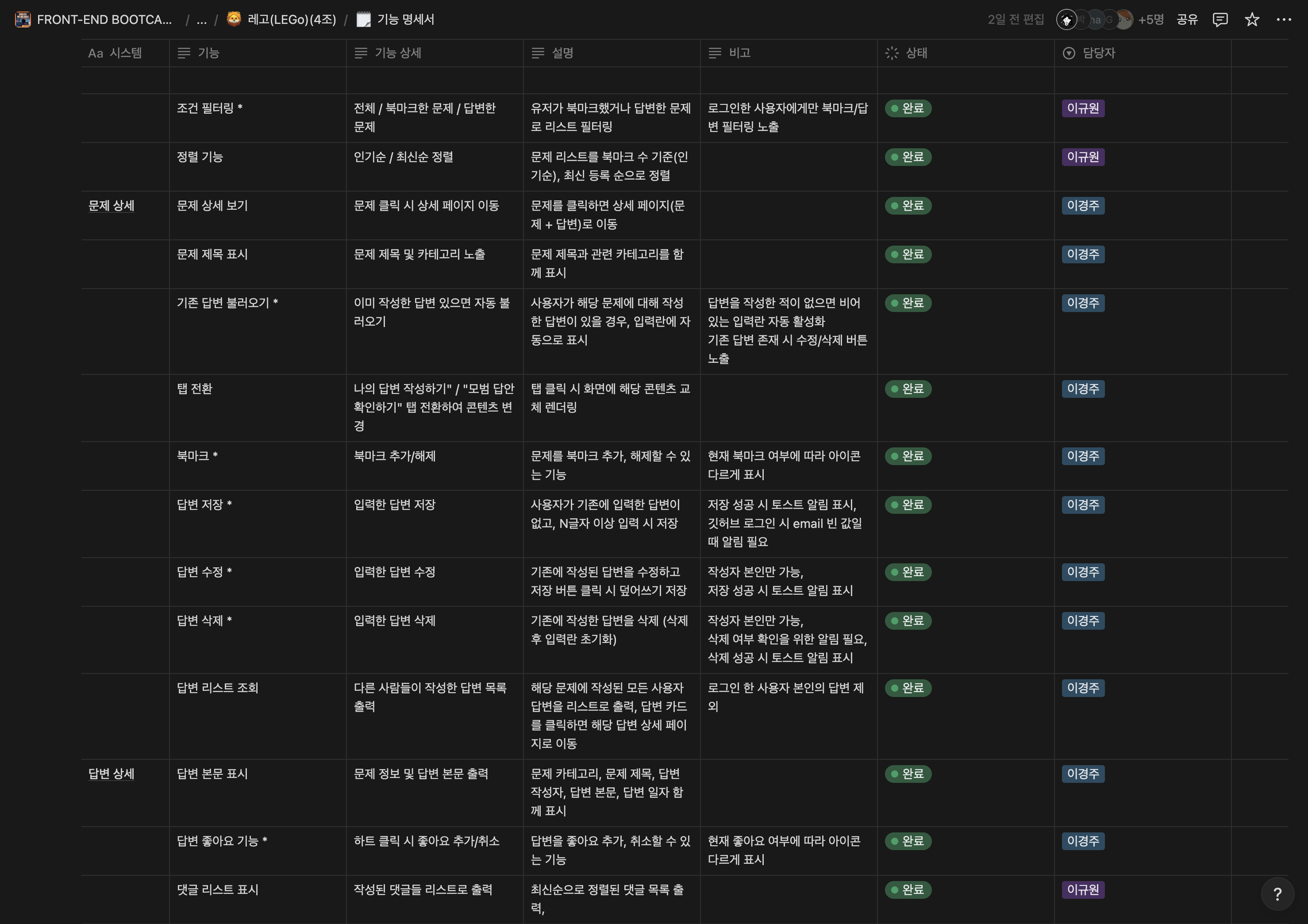
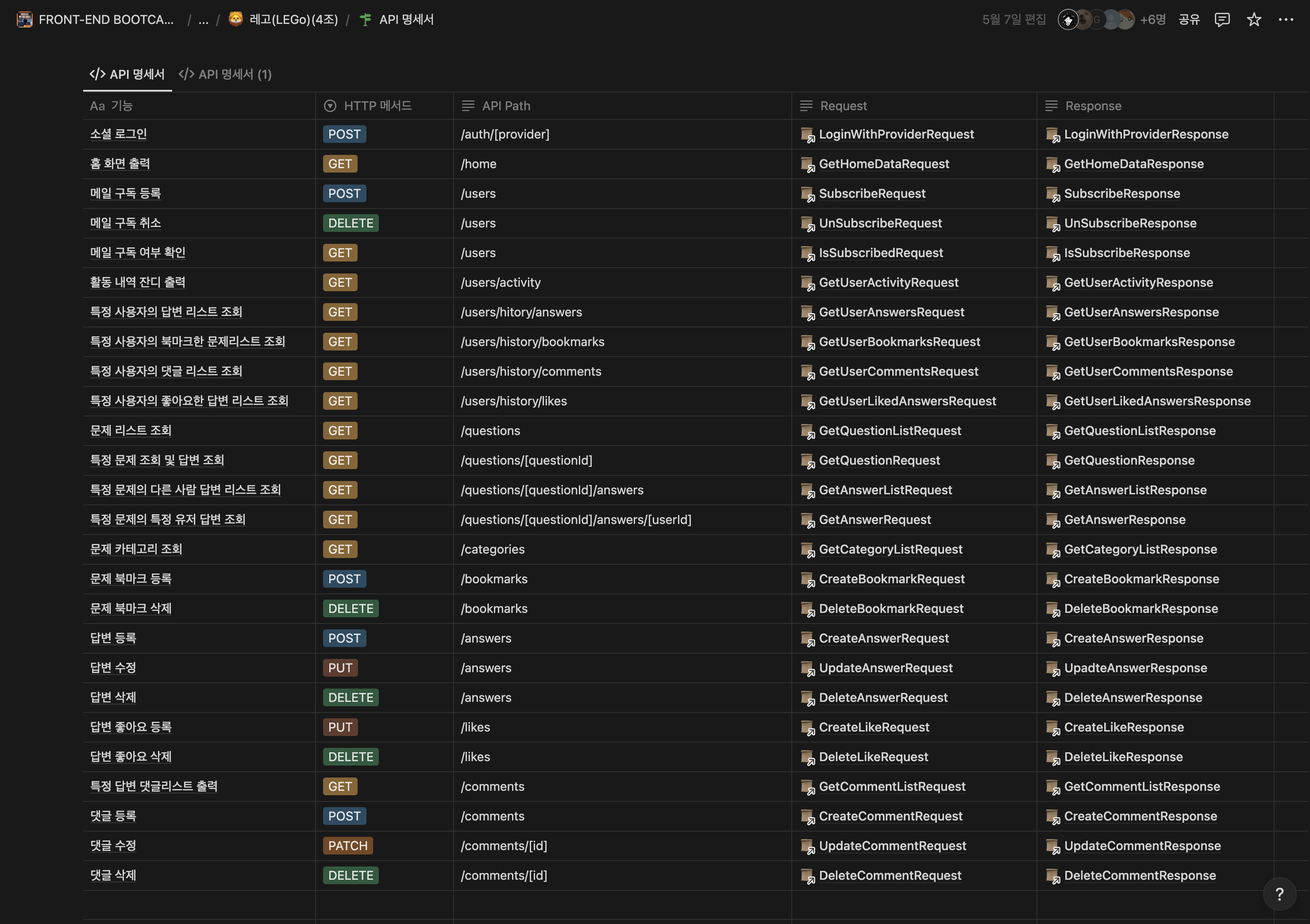
5. 기능 명세서 & api 명세서
💡 배운 점 & 개선 점
-
요청 흐름과 응답 흐름에 대한 이해
단순히 API를 연결하는 기능 구현이 아니라 요청이 들어와서 응답이 나가기까지의 전체적인 흐름을 계층별로 이해할 수 있게 됐다!
요청 흐름
Client → API(Controller) → Request DTO → UseCase → Entity/Service(Repository 포함)
- 클라이언트에서 DB의 특정 행(row)을 조회하거나 조작하기 위한 식별자나 관련 데이터를 포함해 요청을 보낸다.
- API 에서는 사용자의 요청에서 얻은 데이터를 검증하고 유즈케이스가 사용할 수 있는 형태로 정리해서 전달한다.
- 이후 API 라우트에서 UseCase를 실행시킨다.
- UseCase 내부에서 Repository를 호출한다.
- Repository가 Supabase에서 데이터를 조회해서 비즈니스 로직에 필요한 형태로 가공한다.
응답 흐름
Entity → Response DTO → API(Controller) → Client
- UseCase는 Repository로부터 Entity 또는 도메인 객체 형태의 결과를 반환받는다.
- 결과를 API 계층에서 클라이언트에 적합한 응답 포맷(Response DTO)으로 변환한다.
- 클라이언트에 응답을 반환한다.
- 클라이언트는 최종적으로 가공된 응답 데이터를 받는다.
-
타입스크립트 타입은 검증이 아니다
DTO에 타입을 명시해두었기 때문에, 따로 유효성 검증을 하지 않아도 된다고 생각했다. 프로젝트가 끝난 뒤, API 계층에서 DTO에 타입을 명시해도 왜 따로 유효성 검증이 필요한지에 대해 찾아보면서 타입스크립트의 타입은 개발자에게 코드 작성 시 도움을 주는 가이드일 뿐, 실행 (런타임)할 땐 완전히 사라지기 때문에 잘못된 값이 전달되어도 막을 수 없다는 것을 알게됐다.
생각해보니 당연한 부분이다..🤔 앞으로는 controller(API handler) 단계에서 기본 유효성 검증을 빼먹지 않아야지 -
클라이언트가 쓰기 쉬운 형태는 API 계층의 책임!
프로젝트를 진행하면서 구현에 집중하느라 당시에는 명확하게 짚고 넘어가지 못한 부분이 있었다.
Repository가 Supabase에서 데이터를 AnswerView 형태로 가공하는 부분에서 클라이언트 응답 가공은 API(Response DTO)에서 하는 거라고 알고 있었는데, 왜 Repository에서 응답과 비슷한 형태로 데이터를 가공하는지 이해가 어려웠다🤔
프로젝트가 끝나고 확인하면서 UseCase에 전달할 Request DTO만 만들고, 클라이언트에게 응답할 Response DTO는 따로 만들지 않았다는 것을 알게됐다… Repository에서 클라이언트에서 사용할 데이터와 비슷한 형태의 데이터를 가공하는 작업을 했기 때문에, 그 결과(AnswerView)를 그대로 클라이언트에 전달해도 된다고 착각했다.. 🫠
Repository에서의 가공은 DB에서 가져온 데이터를 도메인 계층이 DB 구조에 직접 의존하지 않도록 정리하는 작업이고, API 응답은 클라이언트가 직접 사용하는 최종 포맷이기 때문에 UI에 바로 반영될 수 있도록 날짜 포맷 변환 등의 가공이 별도로 필요한데 이 부분을 클라이언트에서 했고 결과적으로 프론트엔드에 불필요한 책임이 넘어갔다…🤦🏻♀️
이번 경험을 통해 각 계층의 책임과 역할을 보다 명확하게 이해할 수 있었고, 앞으로는 클라이언트에 전달되는 응답 형식은 Response DTO로 정의하고 API 계층에서 응답 데이터를 가공하는 것을 잊지 말고 적용해야겠다 ^^ ;;;
//요부분
const result: AnswerView[] = (data ?? []).map((row) => {
return new AnswerView(
row.email,
row.content,
row.created_at,
row.avatar_url,
row.username,
row.like?.length ?? 0,
row.question_id,
row.question?.[0]?.category?.[0]?.name,
row.question?.[0]?.content,
row.like?.some((l) => l.like_email === userId) ?? false
);
});
return result;
마무리 및 다음 목표
짧은 시간 동안 익숙하지 않은 타입스크립트와 Next.js 클린 아키텍처 구조를 기반으로 함께 프로젝트를 설계하고 완성했다는 점에서 의미 있는 경험이었다~ 이번 프로젝트에서는 익숙하지 않은 구조 자체를 이해하는 데 집중하면서, 기능 구현은 비교적 단순한 CRUD 중심으로 진행했다. 다음 프로젝트에서는 이번 경험을 바탕으로 한층 넓어진 시야를 가지고, 그동안 맡아보지 못했던 로그인, 인증과 같은 주요 기능도 구현해 보고 싶다 ~,~
댓글남기기